SSAS Cube Engine Architecture
The basic things which most of us overlook is to understand the architecture of an underlying technology on which they are working or planning to do. One more important thing to understand first hand is the design principle of that technology we will come on the design principle of data warehousing in some other blog. In this blog we will see the architecture of SSAS in detail:There are few things which you must have heared about optimization in SSAS like Use aggregations, do partitions, use MOLAP model etc.
Have you ever wondered how exactly they speed up or optimize the SSAS performance let's see with the help of architecture of SSAS: Sequence of actions in SSAS these steps may vary sometime due to some external factors but most often they remain same.
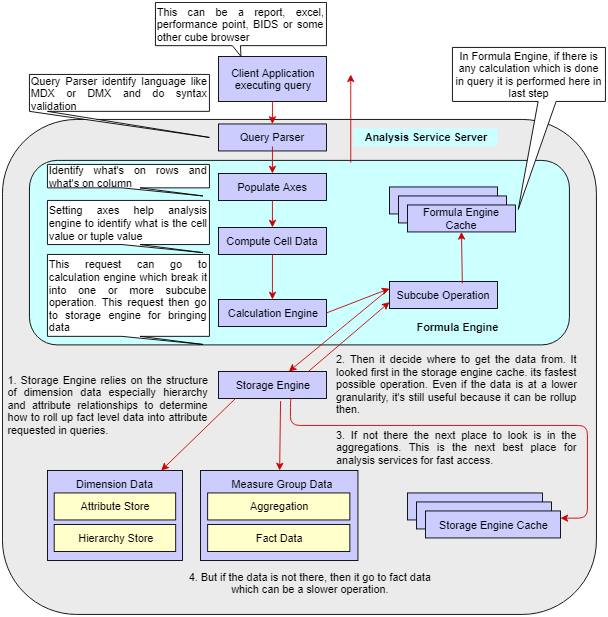
1. At first level is an report or dashboard or SSMS or any other query engine on which user can write MDX or DMX or any other cube browsing query langugae. Once it is executed the request go to Query Parser
2. Query Parser, the job of this is to first interpret the query language, then to validate the syntax once this is done it send the query to Analysis Service Server.
In Analysis Server, the following steps are done
3. Populate axis, here engine identify the dimension or fact attribute which it need to take on axis.
4. Once Axis are set Analysis Engine can identify what are the value it need to take for the combination of these axis. It can calculate the tuple values on the basis of these axis
5. Calculation Engine, Request then arrive on calculation engine which break down the query in one or more sub part according to the design of query and then send them to sub cube operation which is performed in paraller making the process faster.
Once the Calculation Engine, break the query into sub cube operation then sub cube operations are performed on the Storage Engine as follows:
6. Storage Engine, relies on the structure of dimension, attribute's hierarchy and relationship to identify how to roll up the fact data as per the attributes requested in the query.
7. It first looked for the requested data in the storage engine cache which is its fastest possible operation.
8. If the requested data is not present in the cache then the next place to look is the aggregation stored in the cube memory. This is the second best place to load data from.
9. The last place where storage looks is Fact data which is a time consuming process depending on the query. As compared this is the slowest process.
Once the required data is found storage engine send it on the level of sub cube operation
10. Sub Cube operation then send it to Formula Engine Cache, if there is any calculation which is performed in query then it is done here after which the result is send to the resource which send the query.
So this is the reason why it is recommended to do the aggregation and partition in cube.