
In today's rapid world with high network speeds and lot of data. Live Data Streaming is
becoming a domain in itself which requires knowledge of tools which can help user to analyze and
process data in real time
This blog contains detail information about how can we integrate spark and kafka to achieve real
time data analysis

The basic idea behind the introduction of YARN was to split the functionality of Resource Management and
Job scheduling. Prior to YARN, MapReduce-1 was used in which there were 2 component Job Tracker and
Task Tracker where Job Tracker was used to do work of both the job scheduling and task progress reporting,
these 2 are run as 2 different entities in YARN/MapReduce -2 named as Resource Manager and Application Master.
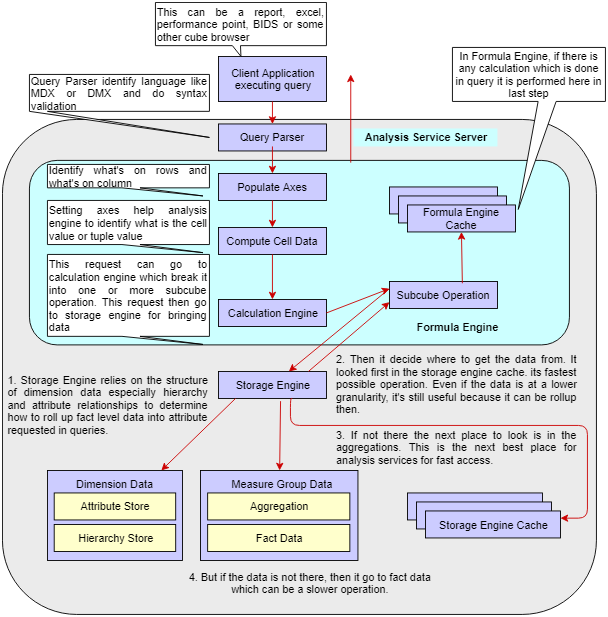
The basic things which most of us overlook is to understand the architecture of an underlying technology on which they are working or planning to do.
One more important thing to understand first hand is the design principle of that technology we will come on the design principle of data warehousing in some other blog.

Apache Flume is a distributed, reliable, and available system for efficiently collecting,
aggregating and moving large amounts of log data from many different sources to a centralized data store.
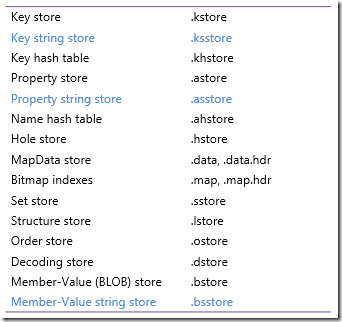
What determines the SSAS cube Size? I was pretty sure about it's answer until I came across a unique scenario while working for one of my client.
So scenario goes like this we were implementing a cube which had 5 facts and 6 dimensions and we decided to implement it using star schema.
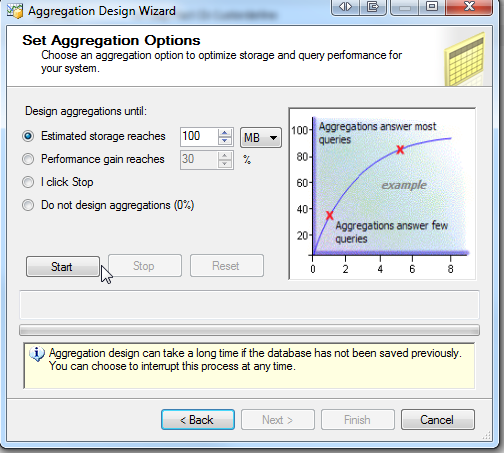
If you have ever searched on how to optimize a SSAS Cube or any similar thing then I am sure you must have heard of Aggregation in SSAS Cube.

If you have ever searched on how to optimize a SSAS Cube or any similar thing then I am sure you must have heard of Aggregation in SSAS Cube.